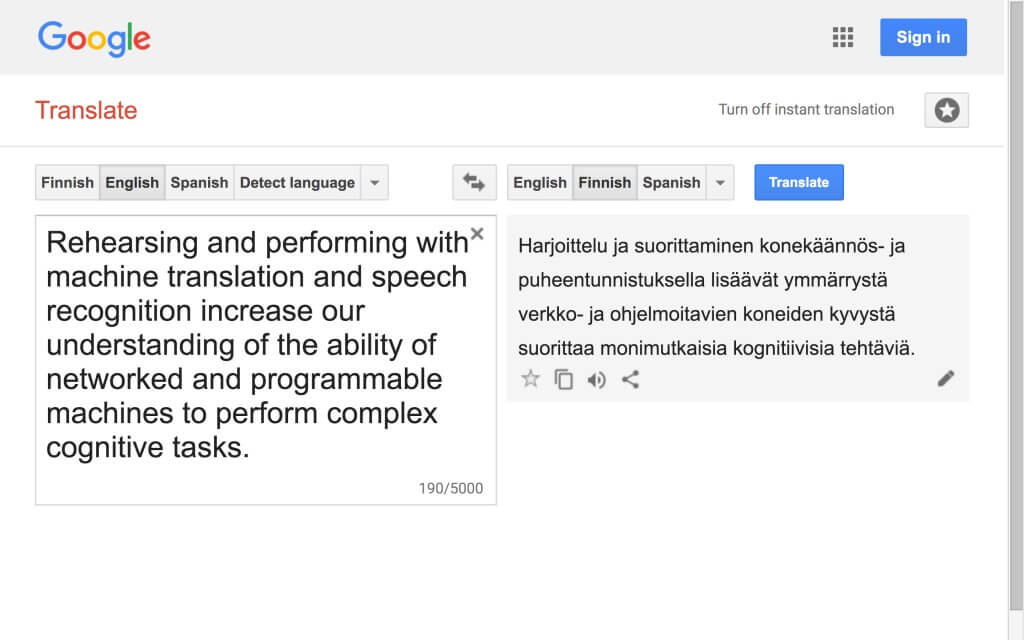
By transferring and repurposing Hayles’s claims for another context, DAR themself puts forward a major argument in fragment 19. By stating that the digital media we use “perform complex cognitive tasks,” they invite a series of questions. The most fundamental of these, of course, is what cognition is, and whether machines can cognize or not. Following Hayles, DAR seems to assert the affirmative.
{kind=link}
Both tasks—machine translation and automated speech recognition—are technically complex, but are they cognitive? If so, in what way or in what sense? What is ultimately the relationship between human and (the purportedly) machine cognition in love.abz/(love.abz)3?
As my questions reveal, I think DAR rushes ahead of things in fragment 19. To my mind, it is not at all obvious that machines perform cognitive tasks in this research. I am ready to accept that, in the research as a whole, digital media serve cognitive purposes. They enable and support cognitive processes and even participate in them, both by their functionality and by their dysfunction (as misrecognitions and mistranslations are often productive for research purposes).
Elsewhere, Hayles has referred to the “in-mixing” of human and machine cognition, as well as to their “collision/conjunction” (Hayles 2008, 16, 23). For this research, the key question is, do digital media perform cognitive tasks or do they, instead, unintentionally acquire cognitive agency in our writing and reading processes. I tilt toward the latter view.
Unintentional Cognitive Agency
In another context (Huopaniemi 2014EN), I have analyzed how, in the part of love.abz documented in video 2.7.1, machine translation and speech recognition (noncognizantly) contribute to the reading and writing process through their noisy results (2.7EN1). In the analysis, I focus particularly on the mechanisms through which speech recognition could be thought to obtain unintentional cognitive agency in the improvisatory group writing. I foreground two concepts that I have used to study the texts written in the performances: turning points and instances of accompaniment.
By turning point (2.7EN2), I refer to a technical shortcoming or statistical error, as a result of which the speech produced by the performer and the text produced by the software do not match. Such recognition errors are very common in multiple-user speech recognition, such as in love.abz/(love.abz)3 (see 1.8). (Depending on language and software, they are still relatively common in single-user speech recognition too.) Here, however, the turning points have a specific and important function, which is why they cannot be regarded as mere technical breaks.
A turning point is a rupture of the writing process, in which the software inserts something that the speaker has not intended or desired. The writer-performer is thus forced to halt and choose either a strategy of compliance or resistance. The former usually entails incorporating the result of the misrecognition into the text, legitimizing it as part of the writing process. The latter, on the other hand, is an attempt to restore authorial control by the means offered by the software, the so-called dictation commands.
Turning points are significant for a discussion of the relationship of human and machine cognition in the case of love.abz/(love.abz)3. If machine cognition in this context occurs in any form, it is precisely because of them. Almost without exception, the human writer-performers include at least something of the noisy material produced by the software. In retrospect, it is usually easy to see that the “foreign” words and phrases produced by the programs have influenced the texts markedly.
Instances of accompaniment (2.7EN2.5), then, are occurrences in which a single writer-performer—or the group as a whole—succeeds in utilizing the rupture resulting from the turning point, i.e. takes a word or phrase invasively inserted as a result of the misrecognition and uses it either immediately or later in the text-in-progress. In instances of accompaniment, the ongoing reciprocal dynamic between the human writer-performers and the software is actualized and initiated in earnest. Here, Hayles’s descriptions of “in-mixing” and “collision/conjunction” begin to resonate, although we must continue to bear in mind that this method utilizes the “dumbness” of the machine rather than its “intelligence” (2.7EN3).
The relationship between the human performers and the algorithmic programs becomes closer when the lines written by the former start to be increasingly indebted to the errors made by the latter. The fact that the performers usually do not react when the software leaves a word or phrase completely unrecognized also speaks of this interdependence. Such non-recognitions—i.e. when the speech signal is left without its textual referent—are rare but not unheard of. My documentation shows that performers often ignore non-recognitions, perhaps because it is easier to react to erroneous recognition than to lack of recognition. Whether or not the machine has the capacity to perform complex cognitive tasks in this connection, its input is prerequisite for the continuation of the described writing.
Notes
2.7EN1
In computational linguistics, “noisy” describes inaccurate or erroneous translations (see e.g. Schlesinger et al. 2008, 577).
2.7EN2
In dramaturgy, turning point stems from the Greek term peripeteia (reversal of circumstances or, indeed, turning point), which—in the eleventh chapter of the Poetics—Aristotle defines as one of three elements of the plot (mythos), along with recognition (anagnorisis), and suffering (pathos) (Heinonen et al. 2012EN).
2.7EN2.5
I borrow the term from Enrique L. Palancar, who in “A typology of split conjunction” describes instances of accompaniment in a linguistic context as, “when both participants act as actors, not as undergoers.” (Palancar 2012, 38).
2.7EN3
Jain et al.’s definition is useful in distinguishing between “intelligent” and “dumb” (or normal) machines: “To be considered as an intelligent machine, the machine has to be able to interact with its environment autonomously. Interacting with the environment involves both learning from it and adapting to its changes. This characteristic differentiates normal machines from intelligent ones. In other words, a normal machine has a specific programmed set of tasks in which it will execute accordingly. On the other hand, an intelligent machine has a goal to achieve, and it is equipped with a learning mechanism to help realize the desired goal” (Jain et al. 2007, 2, emphasis added).