2.7 Fragmentti 19
-
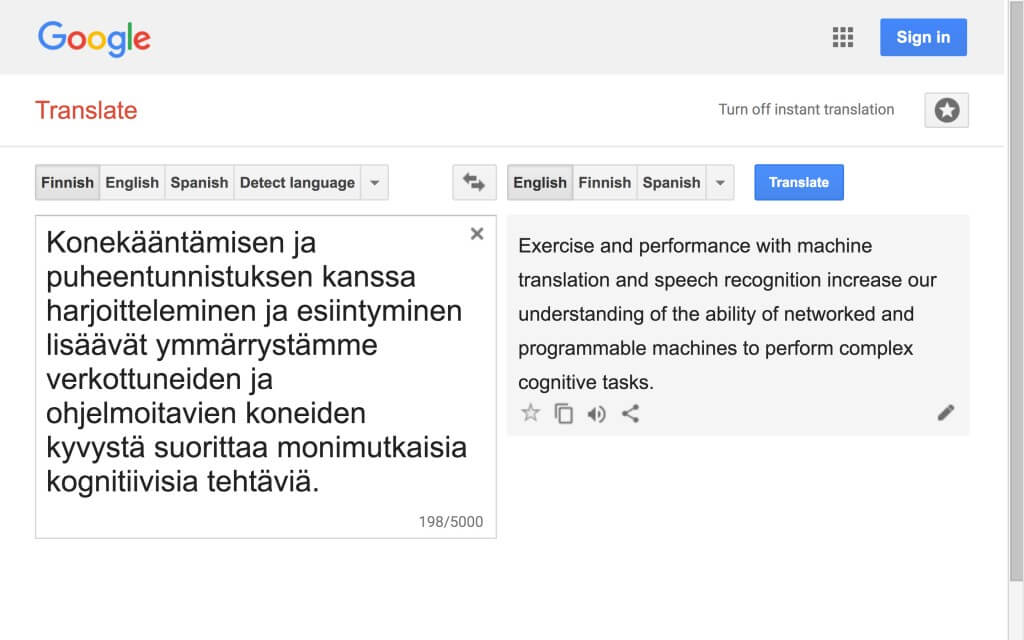
- Fragmentti 19, sovitettu Hayles-katkelmasta 15
Siirtämällä ja mukauttamalla Haylesin väitteet toiseen yhteyteen DAR tulee itse esittäneeksi merkittävän väitteen fragmentti 19:ssä. Toteamuksesta, että käyttämämme digitaaliset teknologiat suorittavat ”monimutkaisia kognitiivisia tehtäviä” seuraa nimittäin joukko kysymyksiä. Näistä perustavanlaatuisin tietysti on, mitä kognitio on ja esiintyykö sitä myös koneilla, kuten DAR Haylesia seuraten näyttäisi väittävän.
Molemmat tehtävät – niin konekääntäminen kuin automaattinen puheentunnistuskin – ovat teknisesti monimutkaisia, mutta ovatko ne kognitiivisia? Millä lailla tai missä mielessä? Mikä on viime kädessä inhimillisen ja (oletetun) koneellisen kognition suhde love.abz/(love.abz)3:ssa?
Kuten kysymyksistäni ilmenee minusta DAR kiirehtii fragmentti 19:ssä asioiden edelle. Minusta kun ei ole lainkaan itsestäänselvää, että koneet suorittavat kognitiivisia tehtäviä tässä tutkimuksessa. Digitaaliset mediat palvelevat tutkimuksen kokonaisuudessa kognitiivista funktiota, sen olen valmis hyväksymään. Ne mahdollistavat ja tukevat kognitiivisia prosesseja ja jopa osallistuvat niihin sekä toimivuutensa että toimimattomuutensa kautta (väärintunnistukset ja -käännökset kun ovat useasti tutkimuksellisesti hedelmällisiä).
Muissa yhteyksissä Hayles on viitannut inhimillisen ja koneellisen kognition “sekoittumiseen” ja “yhteentörmäykseen/kombinaatioon” (Hayles 2008, 16, 23). Tämän tutkimuksen kannalta keskeinen kysymys on, suorittavatko digitaaliset mediat kognitiivisia tehtäviä vai tulevatko ne tahattomasti omaksuneeksi kognitiivista toimijuutta toimiessaan osana harjoittamiamme kirjoitus- ja lukemismetodeja. Kallistun jälkimmäiselle kannalle.
Tahaton kognitiivinen toimijuus
Video 2.7.1 Ote ensimmäisen taiteellisen osan, love.abz:n, videodokumentaatiosta. Huom: Video toistetaan kaksinkertaisella nopeudella.
Toisessa yhteydessä (Huopaniemi 2014) olen analysoinut dokumentoitua love.abz:n osaa, jossa konekäännös ja puheentunnistus (ei-tietoisesti) myötävaikuttavat luku- ja kirjoitusprosessiin meluisten tulostensa kautta (2.7FI1). Analyysissa keskityn erityisesti niihin mekanismeihin, joiden myötä puheentunnistuksen voidaan ajatella saavan tahatonta kognitiivista toimijuutta improvisatorisessa ryhmäkirjoittamisessa. Nostan esiin kaksi käsitettä, joita olen käyttänyt taiteellisissa osissa syntyneiden tekstien jäsentämiseen: käännekohdan ja säestämisen hetken.
Käännekohdalla (2.7FI2) tarkoitan teknistä katkosta tai tilastollista virhettä, jonka seurauksena esiintyjän tuottama puhe ja ohjelmiston tuottama teksti eivät vastaa toisiaan. Tällaiset tunnistusvirheet ovat hyvin yleisiä useiden käyttäjien puheentunnistuksessa kuten love.abz/(love.abz)3:ssa (ks. 1.8). (Kielestä ja ohjelmistosta riippuen ne ovat edelleen suhteellisen yleisiä myös yhden käyttäjän puheentunnistuksessa.) Käännekohdilla on tässä yhteydessä kuitenkin spesifinen ja tärkeä funktio, minkä takia niitä ei voi pitää pelkkinä teknisinä katkoksina.
Käännekohta on kirjoitusprosessin repeämä, jossa ohjelmisto lisää valmisteilla olevaan tekstiin jotakin jota puhuja ei ole toivonut saati aikonut. Kirjoittaja-esiintyjä on pakotettu pysähtymään ja valitsemaan joko myötäilyn tai vastustamisen strategian. Edellinen tarkoittaa yleensä väärintunnistuksen sisällyttämistä tekstiin, sen legitimoimista osaksi kirjoitusprosessia. Jälkimmäinen taas on yritys palauttaa kirjoittajankontrollia ohjelmiston sallimilla keinoilla eli nk. sanelukäskyillä.
Käännekohdat ovat merkityksellisiä pohdittaessa inhimillisen ja koneellisen kognition suhdetta love.abz/(love.abz)3:n tapauksessa, sillä jos koneellista kognitiota tässä yhteydessä ilmenee missään muodossa on se juuri niiden ansiosta. Lähes poikkeuksetta inhimilliset kirjoittaja-esiintyjät sisällyttävät teksteihin ainakin jotakin ohjelmistojen tuottamasta meluisasta aineksesta. Jälkikäteen on yleensä helppo nähdä, että ohjelmien tuottamat ”vieraat” sanat ja ilmaisut ovat vaikuttaneet teksteihin merkittävästi.
Säestämisen hetkillä (2.7FI2.5) tarkoitankin tapauksia, joissa yksittäinen kirjoittaja tai kirjoittajaryhmä kokonaisuudessaan onnistuu hyödyntämään käännekohdasta johtuvaa murtumaa, ts. ottamaan väärintunnistuksen myötä prosessiin tunkeutuneen sanan tai fraasin ja käyttämään sitä tekeillä olevassa tekstissä joko välittömästi tai myöhemmin. Säestämisen hetkissä inhimillisten kirjoittaja-esiintyjien ja ohjelmistojen välinen, jatkuvaan vastavuoroisuuteen perustuva dynamiikka aktualisoituu ja toden teolla käynnistyy. Tässä yhteydessä Haylesin kuvaukset ”sekoittumisesta” ja ”yhteentörmäyksestä/kombinaatiosta” alkavat saada kantavuutta, joskin edelleen on muistettava että menetelmä hyödyntää pikemminkin koneen ”tyhmyyttä” kuin sen ”älykkyyttä” (2.7FI3).
Esiintyjäryhmän ja algoritmisten ohjelmien välinen suhde muuttuu läheisemmäksi, kun edellisten kirjoittamat lauseet alkavat olla yhä enemmän velkaa jälkimmäisten tuottamille virheille. Tästä keskinäisestä riippuvuudesta kielii sekin, etteivät esiintyjät yleensä reagoi silloin kun ohjelmistolta jää jokin lausahdus tai ilmaisu kokonaan tunnistamatta. Tällaiset ei-tunnistamiset – ts. kun puhesignaali jää vaille tekstuaalista vastinettaan – ovat harvinaisia mutta eivät aivan tavattomia. Dokumentaationi osoittaa, että esiintyjät jättävät ei-tunnistamiset yleensä huomiotta, kukaties siksi että on helpompi reagoida virheelliseen tunnistukseen kuin tunnistuksen puutteeseen. Riippumatta siitä, kykeneekö kone suorittamaan monimutkaisia kognitiivisia tehtäviä tässä yhteydessä vai ei, on sen panos kirjoittamisen jatkumisen edellytys.
Viitteet
2.7FI1
Laskennallisessa kielitieteessä ”meluisa” (engl. noisy) kuvaa epätarkkoja, virheellisiäkin käännöksiä (ks. esim. Schlesinger et al. 2008FI, 577).
2.7FI2
Dramaturgiassa käänne juontaa juurensa antiikin Kreikan termistä peripeteia (olosuhteiden vaihtuminen tai käännekohta), jonka Aristoteles määrittelee Runousopin yhdennessätoista luvussa yhdeksi juonen (mythos) osaksi tunnistamisen (anagnorisis) ja kärsimyksen (pathos) ohella (Heinonen et al. 2012).
2.7FI2.5
Lainaan käsitettä Enrique L. Palancarilta, joka ”A typology of split conjunction” -artikkelissaan kuvaa säestämisen ilmentymiä (engl. instances of accompaniment) lingvistisessä kontekstissa seuraavasti: ”Kun molemmat osapuolet ovat toimijoita eivätkä alentujia” (Palancar 2012, 38).
2.7FI3
”Älykkään” ja ”tyhmän” (tai normaalin) koneen eron hahmottamiseen Jain et al.:n määritelmä on hyödyllinen: ”Ollakseen älykäs on koneen voitava olla itsenäisesti vuorovaikutuksessa ympäristönsä kanssa. Ympäristön kanssa vuorovaikutuksessa olemiseen kuuluu sekä ympäristöltä oppiminen että sen muutoksiin sopeutuminen. Tämä ominaisuus erottaa normaalin koneen älykkäästä. Toisin sanoen normaalilla koneella on tietty ohjelmoitujen tehtävien joukko, jonka puitteissa se toimii asianmukaisesti. Älykkäällä koneella taas on tavoite saavutettavanaan ja se on varustettu valitun tavoitteen toteuttamista edesauttavalla oppimismekanismilla” (Jain et al. 2007, 2, painotus lisätty).
{kind=link}
{kind=link}