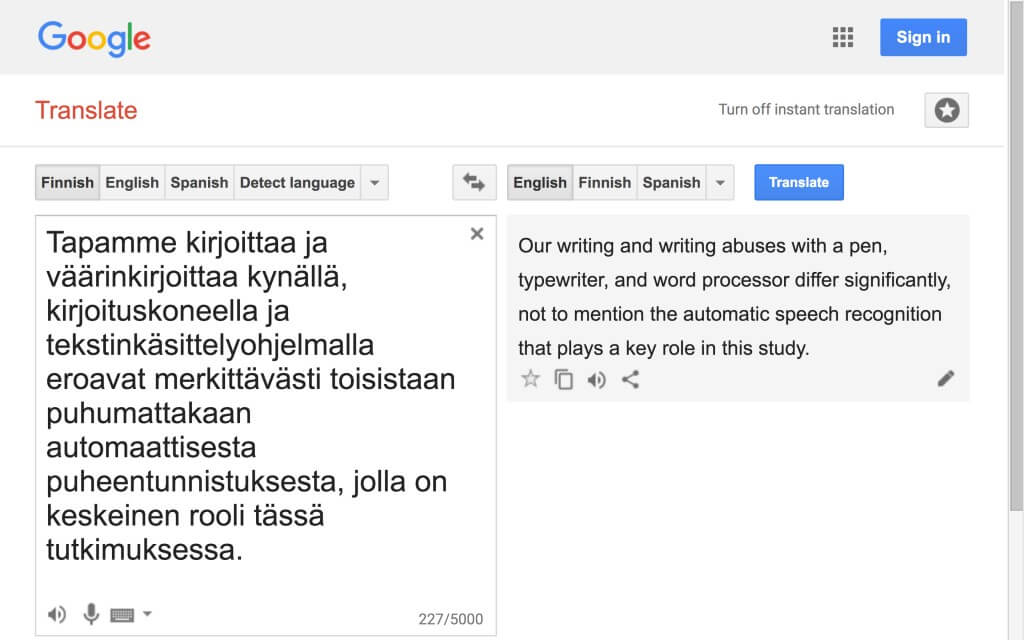
Fragmentti 8:ssa DAR mainitsee neljä teknistä yksilöä – kynän, kirjoituskoneen, tekstinkäsittelyohjelman ja automatisoidun puheentunnistuksen – ja esittää Haylesin vastaavassa katkelmassa (ks. sovitettu Hayles-katkelmasta 7) esittämän väitteen toisinnon: käyttämämme teknologian muoto vaikuttaa ratkaisevasti tapaamme kirjoittaa. Kynä, kirjoituskone ja tekstinkäsittelyohjelma ovat mainituista teknisistä yksilöistä puheentunnistusteknologiaa perinteisempiä ja toimintatapojensa osalta vielä tutumpia – huolimatta siitä, että viimeksi mainitusta on tietokoneiden ja erityisesti älypuhelinten kehityksen myötä tullut nopeasti kaikkialla läsnä oleva ominaisuus (1.8FI1). Puheentunnistusteknologia on myös tekninen yksilö, jonka tämän tutkimuksen taiteelliset osat ovat ottaneet osaksi teknisiä kokonaisuuksiaan irrottaen sen alkuperäisestä käyttötarkoituksestaan ja käyttämällä sitä uusiin, esityksellisiin tarkoituksiin Simondonin konkretisaation kaltaisen prosessin kautta (1.8FI2).
{kind=link}
Yleistäen voidaan sanoa, että tässä tutkimuksessa tarkastellaan luovia, esityksellisiä kirjoituspraktiikkoja, joissa yhdistyvät niin inhimillinen kuin koneellinenkin työpanos ja jotka hyödyntävät tiettyjen digitaalisten mediumien erityisiä toimintaominaisuuksia. Puheentunnistusteknologia ei toimi tässä yhteydessä vain teknisenä yksilönä ja kirjoitusvälineenä, vaan mediumina jonka käyttömahdollisuuksia ja rajoituksia kirjoituspraktiikat hyödyntävät. Tässä jaksossa video-otteet tutkimusprosessin aikana toteutetuista harjoituksista ja esityksistä osoittavat, miten tätä nimenomaista teknistä yksilöä, automatisoitua puheentunnistusta, voidaan käyttää taiteellisena mediumina. Lisäksi näytteet antavat yleiskuvan joistakin tutkimuksen aikana kehitetyistä kirjoituspraktiikoista ja siitä miten ne eroavat toisistaan.
Näyte 1: ilman puheentunnistusta kirjoittaminen (2:52)
Ensimmäisen näytteen (video 1.8.1) tarkoitus on toimia vertailukohtana alla oleville näytteille, sillä siinä kirjoitetaan puheentunnistuksen sijaan näppäimistöä ja tekstinkäsittelyohjelmaa käyttäen. Näyte on kirjoittaja-esiintyjä Teemu Miettisen ja minun Kiasmassa vuonna 2012 esittämästä julkisesta harjoituksesta (1.8FI4). Harjoitus on osa tutkimuksen ensimmäisen taiteellisen osan love.abz:n valmisteluprosessia. Äänettömässä videossa Teemu kirjoittaa proosaa ja draamaa yhdistävää tekstiä, joka liittyy väljästi näytelmääni Rakkauden ABZ (Huopaniemi 2015FI) (1.8FI5).
Dokumentissa todistamme Teemun ponnistelua tekstin tuottamisessa (1.8FI5.5). Osa tästä ponnistelusta on tyypillistä näppäimistön ja tekstinkäsittelyohjelman käytön yhteydessä ilmenevää väärinkirjoittamista: toistuvat lyöntivirheet ja korjaukset. Osa siitä taas liittyy julkisen kirjoitustilanteen erityisluonteeseen – esimerkiksi pitkähkö tauko ennen kirjoittamisen aloittamista – ja metafiktiivisen narratiivin luomisen kompleksisuuteen.
Taustalla näkyvä ruutunäkymä on Kiasman seinälle projisoitu. Yleisö seuraa projisoinnista 30-minuuttisen kirjoitusprosessin etenemistä. Teemu seisoo korkean pöydän äärellä ja tietokoneen kamera kuvaa hänen kasvojaan sekä ylävartaloaan. Esityksessä teksti ilmestyy reaaliajassa näyttöön. Teemun kirjoittamisessa ilmenevät keskeytykset, epäuskoiset tai huvittuneet katsahdukset sekä hiusten ja kasvojen haromiset kielivät tehtävän vaativuudesta. Teemu sisällyttää tekstiinsä useita viitteitä näytelmääni: henkilönimiä (isot kirjaimet), samankaltaisia tilanteita ja repliikkejä. Tekstissä katkelmallisesti rakentuva draama näyttää koskevan narratiivin itsensä syntyä tai syntymättömyyttä, mikä heijastelee näytelmäni kohtausten seisahtunutta luonnetta. Teemun esittämän tekstin voi näin ollen katsoa olevan eräänlainen näytelmäni improvisoitu sovitus tai käännös.
Näyte 2: yksilökirjoittaminen puheentunnistuksella (2:06)
Toisessa näytteessä (video 1.8.2) demonstroidaan puheentunnistuksella tapahtuvaa yksilökirjoittamista. Se on osa samaa ensimmäisen taiteellisen osan valmisteluprosessia kuin edellinen näyte (1.8FI7). Videossa kirjoitan yksin improvisoitua kohtausta englannin kielellä. Puheentunnistuksen lisäksi käytän tässä harjoitteessa myös koneellista käännösohjelmaa, joka kääntää kohtauksen saksaksi sitä mukaa kun kirjoitan sitä.
Jo kohtauksen ensimmäistä riviä kirjoittaessani kohtaan puheentunnistuksella kirjoitettaessa tiuhaan toistuvan tilanteen: näytölle ilmestyvä teksti ei vastaa sitä mitä olen sanonut. Tutkimuksen taiteellisissa osissa tämänkaltaisilla epävastaavuuksilla on keskeinen rooli (1.8FI8). Tässä nimenomaisessa kaksiminuuttisessa näytteessä reagoin niihin kauttaaltaan samalla tavalla: sen sijaan, että korjaisin epävastaavuudet pyrin sisällyttämään niiden tuloksina syntyneet sanat rakenteilla olevaan repliikkiin. Tämänkaltaisella inhimillisen kirjoittajan ja tietokoneen välisellä yhteispelillä on niin ikään merkittävä rooli taiteellisissa osissa esillä olevassa kirjoitusmetodissa (1.8FI9).
Näyte kuvastaa sitä, miten väärinkirjoittaminen muuttuu siirryttäessä tekstinkäsittelyohjelmalla ja näppäimistöllä kirjoittamisesta puheentunnistukseen. Siinä missä ensimmäisessä näytteessä näemme näppäilemällä kirjoitettaessa tyypillisesti ilmeneviä väärinlyöntejä – virheitä, jotka havainnollistavat käsi-näppäimistö-käyttöliittymän toimintaa –, tässä toisessa näytteessä todistamme ääni-ohjelmisto-käyttöliittymän toimivuutta ja toimimattomuutta. Olennainen ero on, että jälkimmäisessä inhimillisellä kirjoittajalla on vähemmän välitöntä kontrollia sillä tekstin korjaaminen äänellä on yleensä monimutkaisempi ja hitaampi prosessi kuin sormilla näppäiltäessä (1.8FI9.5).
Näyte 3: ryhmäkirjoittaminen (2:46)
Kolmannessa näytteessä (video 1.8.3) näemme esimerkin puheentunnistuksella ja koneellisella käännösohjelmalla toteutetusta ryhmäkirjoittamisesta. Ote on tutkimuksen toisen taiteellisen osan, (love.abz)3:n, esityksestä. Näytteessä esiintyvät Josep Caballero García, Lee Meir ja Ania Nowak. Puheen ja tekstin epävastaavuudet toistuvat tässäkin näytteessä, nyt vielä runsaampina kuin edellisessä. Kohtauksen kaksi ensimmäistä lausetta – jotka ovat molemmat näyttämöohjeita – ovat oireellisia: ensimmäisen puhujan Leen sanoessa ”Wir sind in Lima” (”olemme Limassa”) näytölle ilmestyy sanat ”Wir sind ein Lehmann”. Josep jatkaa sanomalla: ”Auf den Machu Picchu” (”Machu Picchulla”). Ohjelmisto tuottaa vaikeaselkoisen lauseen: ”Auf dem Matschbezug”.
Verrattuna edelliseen näytteeseen ryhmäkirjoittaminen tuo kuitenkin selvästi oman dynamiikkansa puheentunnistuksella kirjoittamiseen, koska kirjoittajia on kolme kertaa enemmän ja näin ollen myös inhimillisen kirjoittajien ja tietokoneen välisiä mahdollisia vuorovaikutuksia moninkertaisesti enemmän. Tekniikka koettelee myös digitaalista mediaa toisella tapaa kuin yksilökirjoittaminen, sillä ohjelma on suunniteltu tunnistamaan yhden äänen kerrallaan (1.8FI13). Siksi ei ole yllättävää, että epävastaavuuksia esiintyy useammin ryhmä- kuin yksilökirjoittamisessa.
Ryhmäkirjoittamisen kompleksisuutta kuvastaa se, että toisin kuin edellisessä näytteessä tässä esiintyjät käyttävät ohjelman heille suomia tekstuaalisen kontrollin mahdollisuuksia. Ihmisen ja tietokoneen välisen vuorovaikutuksen lisäksi inhimillisten kirjoittajien keskinäisen vuorovaikutuksen merkitys korostuu ryhmäkirjoittamisessa, kuten näyte 3 osoittaa: päällekkäin puhumiset, tauot, vuorottelu ja yritys löytää yhteistä rytmiä tai ”punaista lankaa”. Hyvällä syyllä voidaan sanoa, että tällaisessa digitaalisessa ryhmäkirjoittamisessa yhtenäisen kerronnan rakentaminen on paljon haastavampaa kuin yksilökirjoittamisessa vaikka esiintyjät ovatkin sopineet joistakin suuntaviivoista ennen improvisaatiota (1.8FI14).
Näyte 4: koneellinen kirjoittaminen (0:57)
Neljäs ja viimeinen näyte (video 1.8.4) eroaa monessa suhteessa edellisistä. Ylen latinankielisestä radiolähetyksestä tehty taltiointi syötetään videossa puheentunnistusohjelmistoon, joka on ohjelmoitu tunnistamaan englannin kieltä. Koe on kahden ensimmäisen näytteen tavoin vuodelta 2012 eli ensimmäistä taiteellista osaa edeltävältä ajalta.
Nuntii Latini muuttuu puheentunnistajan ”kääntämänä” (1.8FI15.5) vaikeaselkoiseksi proosarunoudeksi. Yhtä tummanpuhuvaa poikkeusta lukuun ottamatta – ohjelmisto tunnistaa Syyrian presidentin Bashar al-Assadin sukunimen jälkimmäisen osan oikein – epävastaavuus puheen ja tekstin välillä on täydellinen.
Näyte 4:n kohdalla ei voi enää puhua siitä, että puheentunnistaja toimisi kirjoittamisen mediumina, sillä se vastaa itse kirjoittamisesta. Äänitiedoston ja ohjelmiston välisestä käyttöliittymästä puuttuu inhimillinen kirjoittaja, jonka kognitiiviset ja keholliset toiminnot (näppäileminen, puhuminen) muodostavat edellä kuvattujen kirjoitustekniikoiden toiminnallisuuden toisen puoliskon. Epävastaavuuden sijaan näyte 4:n kohdalla onkin mielekkäämpää puhua käyttöliittymän itsenäisestä kapasiteetista tuottaa uutta tekstiä, kun sitä manipuloidaan tällä tavoin. Tekstin ei tulekaan vastata puhetta, sillä puheen funktio on toimia ärsykkeenä joka käynnistää tekstin tuottamisen algoritmisen prosessin.
Näyte 4:ssäkin on kyse luovuudesta, joskaan ei ohjelmoidusti aikaansaadusta laskennallisesta luovuudesta (1.8FI16). Sen sijaan video demonstroi mitä olen tämän tutkimuksen myötä ryhtynyt kutsumaan koneen satunnaiseksi luovuudeksi. Ohjelmisto tuottaa tekstiä silloinkin, kun sitä ei käytetä tarkoitetulla tavalla. Näin ollen syntyy porsaanreikä, jota hyödyntämällä satunnaisen luovuuden tuottaminen on mahdollista. Samanlaista satunnaista luovuutta käytetään laajasti myös tutkimuksen taiteellisissa osissa, joskaan ei sillä tapaa kuin tässä äärimmäisessä esimerkissä. Laskennallisella luovuudella lienee tulevaisuudessa merkittävä rooli koneellisen kirjoittamisen kehityksen kannalta (1.8FI17), mutta kuten tässä jaksossa esitetyt näytteet osoittavat on tämän tutkimuksen painopiste muualla.
Viitteet
1.8FI1
Puheentunnistus on itse asiassa laajempi termi, jolla viitataan ”kieli- ja puheteknologian alaan kuuluviin hahmontunnistusmenetelmiin, joiden avulla tietokone voi tunnistaa ihmisten puhetta”. Tässä tutkimuksessa käytetään lähes yksinomaan puheentunnistuksen sanelusovellukseksi kutsuttua alalajia, jossa ”kone pyrkii muuttamaan ihmisen vapaan puheen tekstiksi”. (Wikipedia 16.2.17.)
1.8FI2
Oltuani aluksi haluton ottamaan puheentunnistuksen mukaan tutkimusprosessin toiseksi merkittäväksi digitaaliseksi teknologiaksi konekääntämisen ohella huomasin nopeasti, että se tarjosi enemmän esityksellisiä mahdollisuuksia kuin konekääntäminen yksin. Puheentunnistus osoittautui riittävän joustavaksi muuttuakseen osaksi rakenteilla olevaa teknistä kokonaisuutta ja toisaalta myös tarpeeksi lujaksi antaakseen meille teknisen kehyksen, jonka puitteissa saatoimme tutkia kirjoittamista.
1.8FI4
love.abz, kaksi julkista harjoitusta, Esityskomposti-performanssitapahtuma Kiasman galleriatilassa. Ohjaus ja suunnittelu: Otso Huopaniemi. Esiintyjä: Teemu Miettinen. Kuraattorit: Elina Latva, Nora Rinne ja Jonna Strandberg. AV-suunnittelu ja toteutus: Heikki Paasonen.
1.8FI5
Rakkauden ABZ:n koneellisesti käännetyt kohtaukset toimivat taiteellisissa osissa harjoitetun improvisatorisen kirjoittamisen heräteteksteinä (ks. 2.2 ja 3.4).
1.8FI5.5
On syytä lisätä, että Teemu on esimerkillinen kirjoittaja joka tuottaa korkeatasoista tekstiä, kuten ovat kaikki tutkimuksen taiteellisiin osiin osallistuneet kirjoittaja-esiintyjät. Heidän kamppailunsa paljastaa enemmän tehtävien problematiikasta kuin mistään henkilökohtaisista puutteista.
1.8FI7
Tämä nimenomainen harjoite on elokuun 30. päivältä 2012. Tein sen silloisessa työhuoneessani.
1.8FI8
Kutsun tilanteita, joissa epävastaavuudet ilmenevät käänteiksi tai käännekohdiksi, sillä ne pakottavat kirjoittaja-esiintyjän joko hyödyntämään syntynyttä epävastaavuutta tai poistamaan sen (sikäli kuin tämä on mahdollista) (ks. 2.7).
1.8FI9
Tilanteita, joissa inhimillinen kirjoittaja-esiintyjä käyttää onnistuneesti epävastaavuuden tuloksena syntynyttä ei-aiottua tekstiä kutsun säestämisen ilmentymiksi (ks. 2.7).
1.8FI9.5
Harjoituksissa ja esityksissä havaitsemme, että puheentunnistusohjelmiston metakomennot toimivat vaihtelevalla luotettavuudella. Yksittäisen sanan tai fraasin poistamiseen tarkoitetut komennot toimivat keskimäärin hyvin, mutta sitä monimutkaisemmat tai epätavallisemmat komennot vaihtelevasti – ja usein viiveellä.
1.8FI13
Käyttämämme puheentunnistus on ”puhujariippuvaista” ja vaatii tässä kuvattua ennakkokalibrointia: ”Jotkut puheentunnistusjärjestelmät käyttävät ’harjoittelua’ (jota myös ’kirjoittautumiseksi’ kutsutaan), jossa yksittäinen puhuja lukee tekstiä tai yksittäisen sanaston järjestelmään. Järjestelmä analysoi henkilön äänen erityisyyttä ja käyttää sitä kyseisen henkilön puheen tunnistamisen hienosäätöön, mikä lisää tarkkuutta. ’Puhujariippumattomiksi’ kutsutaan sellaisia järjestelmiä, jotka eivät käytä tämänkaltaista harjoittelua” (ks. video 3.4.1) (Wikipedia 16.2.17).
1.8FI14
Improvisaatiota edeltävät kokoontumiset – jotka muistuttavat amerikkalaisen jalkapallon huddle-neuvotteluja – lisätään toisessa taiteellisessa osassa (love.abz)3:ssa, jotta esiintyjillä olisi enemmän valtaa improvisaatioihin. Improvisaatiot kun ovat ensimmäistä taiteellista osaakin vaativampia, sillä niitä on useita samanaikaisesti kuten videossa kuuluva taustahälinä osoittaa.
1.8FI15.5
Tai kääntämänä ilman lainausmerkkejä, sillä tämän tutkimuksen valossa on perusteltua ajatella puheentunnistusta yhtenä koneellisen kääntämisen muotona.
1.8FI16
Kuten Hannu Toivonen kirjoittaa, laskennallinen luovuus on keinoälyn kaksonen: ”Siinä missä keinoäly tutkii miten suorittaa tehtäviä, joita ihmisen suorittamina pidettäisiin älykkäinä, laskennallinen luovuus tutkii suorituksia, joita ihmisen suorittamina pidettäisiin luovina” (Toivonen & Gross 2015, 265).
1.8FI17
Muun muassa Brains on Art -ryhmä on luonut Brain Poetry -nimisen runogeneraattorin, joka muuntaa käyttäjän aivosähkökäyrän runoksi. Ks. brainsonart.wordpress.com/2013/10/18/brain-poetry-2013