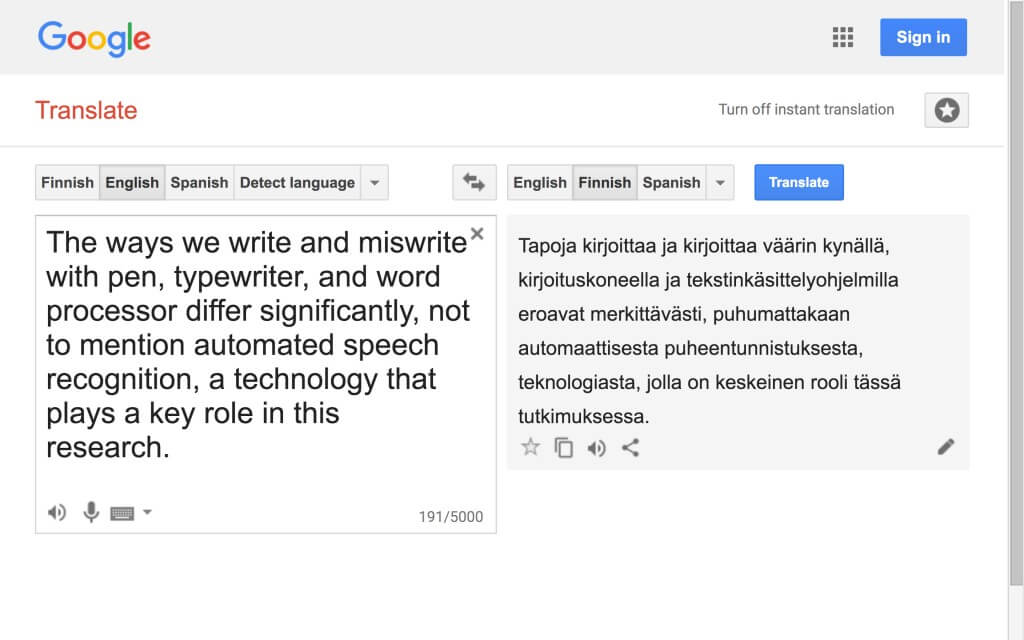
In fragment 8, DAR mentions four technical individuals—pen, typewriter, word processor, and automated speech recognition—and presents a variant of the claim Hayles makes in the corresponding passage (see adapted from Hayles passage 7): the technology we use has a decisive impact on the way we write. Of the mentioned technical individuals, pen, typewriter, and word processor are more traditional and perhaps still more familiar in regards to their functioning than speech recognition—despite the fact that the latter has, with the development of computers and smart phones in particular, rapidly become a ubiquitous feature (1.8EN1). Speech recognition technology is also one of the technical individuals that the artistic parts of this research have taken into their technical ensembles, detaching it from its original purpose and using it for new, performative purposes through a process akin to Simondon’s concretization (1.8EN2).
{kind=link}
In general, it can be said that this research examines writing practices that combine the creative, performative work of both humans and machines and that take advantage of the specific operating characteristics of certain digital media. Speech recognition technology is therefore not only a technical object and a tool in this context, but a medium whose affordances and limitations the writing practices exploit. In this section, video excerpts from rehearsals and performances carried out over the course of the research process demonstrate how this particular technical object, automated speech recognition, can be used as an artistic medium. In addition, the samples give an overview of some of the writing practices developed in this research and the ways in which they differ from each other.
SAMPLE 1: Writing without Speech Recognition (2:52)
The first sample (video 1.8.1) serves as a point of reference for the samples below, as it shows writing with keyboard and word processor rather than with speech recognition. The excerpt is from a public rehearsal writer-performer Teemu Miettinen and I performed in Kiasma Museum of Contemporary Art, Helsinki, in 2012 (1.8EN4). The rehearsal is part of the process leading up to the first artistic part, love.abz. In the silent video, Teemu writes text loosely related to my play Rakkauden ABZ (“An ABZ of Love”) (Huopaniemi 2015EN) (1.8EN5), combining elements of prose and drama.
In the document, we witness Teemu’s struggle with producing text (1.8EN5.5). Part of this struggle is typical of writing with keyboard and word processor: repetitive typing errors and corrections. Part of it, on the other hand, involves the specific nature of the public writing situation—such as the fairly long pause before starting to write—and of creating a complex metafictional narrative.
The screen view visible in the background is projected on the museum’s wall. The audience follows the progression of the 30-minute writing process by way of the projection. Teemu stands at a high table, and his computer’s camera records video of his face and upper body. The text appears in the projection in real time. The interruptions occurring during Teemu’s writing, along with his disbelieving and amused glances, stroking of hair and face, tell of the difficulty of the task. In his text, Teemu makes several references to my play: character names (capital letters), similar situations and lines. The text’s fragmentary drama seems to deal with the emergence or disappearance of narrative itself, which also reflects the stagnant nature of the scenes in the play. Therefore, the text performed by Teemu may be regarded as an improvisatory adaptation or translation of the play.
Sample 2: Individual Writing with Speech Recognition (2:06)
The second sample (video 1.8.2) demonstrates using speech recognition for individual writing. It is part of the same preparation process for the first artistic part as the previous sample (1.8EN7). In the video, I write an improvised scene in English, alone. In addition to speech recognition, in this exercise I also use machine translation to translate the scene into German as I write it.
Already while writing the first line of the scene, I encounter a frequently recurring situation when writing with speech recognition: the text that appears on the screen does not correspond with what I have said. In the artistic parts of this research, such mismatches play a key role (1.8EN8). Throughout this particular two-minute excerpt, I react to the mismatches in the same way, by attempting to include the words resulting from the mismatches in the scene instead of trying to correct the dissimilarity. Such interplay between human writer and computer is also central to the writing method on display in the artistic parts (1.8EN9).
The sample illustrates how miswriting changes when moving from writing with keyboard and word processor to speech recognition. While in the first sample we see typing errors typically occurring when writing with a keyboard, errors that exemplify the operations of the hand-keyboard interface, here we witness the functioning and non-functioning of the voice-software interface. The crucial difference is that in the latter the human writer has less immediate control over the mismatch, because correcting text with voice is usually a more complicated and slower process than when writing with fingers on keyboard (1.8EN9.5).
Sample 3: Group Writing (2:46)
In the third sample (video 1.8.3), we see an example of group writing carried out through the use of speech recognition and machine translation. The excerpt is from a performance of the second artistic part,(love.abz)3. The performers are Josep Caballero García, Lee Meir, and Ania Nowak. Mismatches between speech and text recur also in this sample and now they are more abundant than in the previous sample. The first two sentences of the scene, both stage directions, are indicative: when Lee, the first performer to speak, says, “Wir sind in Lima” (“We’re in Lima”), the words “Wir sind ein Lehmann” appear on the screen. Josep continues by saying, “Auf den Machu Picchu” (on the Machu Picchu). The software produces the obscure sentence, “Auf dem Matschbezug.”
However, in comparison to the previous sample, the group writing situation in sample 3 brings a distinct dynamic of its own to writing with speech recognition, as there are three times as many writing actors and thus exponentially more possible interactions between human writers and the computer. This technique also puts the digital media to the test in another manner than individual writing, as the software is only programmed to recognize one voice at a time (1.8EN13). Unsurprisingly, mismatches occur more frequently when writing of this kind is performed by a group rather than an individual.
Reflecting the complexity of group writing, the performers utilize the possibilities for textual control offered by the program, unlike in the previous sample. As the excerpt demonstrates, in addition to human-computer interaction, the significance of human-human interaction is highlighted in group writing: speaking on top of each other’s voices, pausing, alternating, and trying to find a writing rhythm or common thread as a group. It is safe to say that in this digital group writing, constructing a coherent narrative is far more challenging than when writing alone, even though the performers have conferred with each other before the improvisation and agreed on some guidelines (1.8EN14).
Sample 4: Machine Writing (0:57)
The fourth and final sample (video 1.8.4) differs in many respects from the above. In the video, a recording of a Latin-language broadcast is fed to speech recognition software that is programmed to recognize English. Like the first two samples, sample 4 also dates back to 2012, i.e. the period preceding the first artistic part.
Nuntii Latini—the news program broadcast in Latin by Yle, the Finnish Broadcasting Company—is “translated” (1.8EN15.5) into obscure prose poetry. With one daunting exception—the software correctly identifies the latter part of Syrian President Bashar al-Assad’s last name—the mismatch between speech and text is complete here.
In the case of sample 4, it would seem impossible to speak of speech recognition as medium anymore, as it is responsible for the text itself. The interface of the audio file and software lacks the human writer, whose cognitive and bodily functions (typing, speaking) constitute the other half of the functioning of the writing techniques above. Rather than speaking of mismatch in connection with sample 4, then, it would seem more appropriate to point to the independent capacity of the interface to produce new text when manipulated in this way. The text does not even need to match the speech, as the function of the latter is to act as a stimulus that triggers the process of algorithmic text production.
What occurs in sample 4 is also a form of creativity, although not computational creativity as such (1.8EN16). Instead, the video demonstrates what I have over the course of this research come to call the machine’s random creativity. The software generates text even when used in unintended ways. This creates a loophole that allows for the production of random creativity. Similar random creativity is also used throughout the artistic parts of this research, although not in the same way as in this extreme example. Computational creativity is likely to play a significant part in the future of machine writing (1.8EN17), but as the samples presented in this section indicate the focus of this research is elsewhere.
Notes
1.8EN1
Speech recognition is in fact a broad term that refers to “the inter-disciplinary sub-field of computational linguistics that develops methodologies and technologies that enables [sic] the recognition and translation of spoken language into text by computers.” This research utilizes almost exclusively the “speech to text” (STT) function of speech recognition. (Wikipedia 16 February 2017).
1.8EN2
After initially being reluctant to take speech recognition on as the second major digital technology of the research process, after machine translation, I quickly noticed that it offered performative possibilities that machine translation alone did not. In this sense, speech recognition proved to be flexible enough to be adopted into the technical ensemble under construction, while also firm enough to provide us with a technical framework within which we could explore writing.
1.8EN4
love.abz, two public rehearsals, Performance Compost performance event in Kiasma Gallery. Conceived and directed by: Otso Huopaniemi. Performer: Teemu Miettinen. Curators: Elina Latva, Nora Rinne, and Jonna Strandberg. AV design: Heikki Paasonen.
1.8EN5
Machine translated excerpts of An ABZ of Love act as stimulus texts for most of the improvisatory writing performed in love.abz and (love.abz)3 (see 2.2 and 3.4).
1.8EN5.5
I should add that Teemu is an exemplary practitioner producing cutting-edge text, as are all the writer-performers that appear in the artistic parts of this research. Their struggles reveal more about the problematics of the tasks than any personal deficiencies.
1.8EN7
This particular exercise is from 30 August 2012, carried out in my then studio.
1.8EN8
I propose calling situations in which such mismatches occur turning points, as they force the writer-performer to either take advantage of the resulting text or to attempt to remove it (see 2.7).
1.8EN9
I refer to situations in which the writer-performer successfully utilizes the unintended text (mismatch) as instances of accompaniment (see 2.7).
1.8EN9.5
This observation is based on exercises and performances in which we have experienced the varying degrees of reliability of voice recognition software meta-commands. Commands intended for the removal of a single word or phrase usually work well, but more complex or unusual commands are less reliable—and often involve a delay.
1.8EN13
The speech recognition software we use is “speaker dependent” and requires the type of training described here: “Some SR systems use ‘training’ (also called ‘enrollment’) where an individual speaker reads text or isolated vocabulary into the system. The system analyzes the person’s specific voice and uses it to fine-tune the recognition of that person’s speech, resulting in increased accuracy. Systems that do not use training are called ‘speaker independent’ systems” (see video 3.4.1) (Wikipedia 16 February 2017).
1.8EN14
The pre-improvisation conferrals—resembling the “huddles” that characterize American football—are added in the second artistic part, (love.abz)3, in order to give the performers a sense of more control over the improvisations. The improvisations are even more challenging than in the first artistic part, as there are several of them happening in the performance space at once, as the background noise in the video attests.
1.8EN15.5
Or translated without quotation marks, as in the light of this study it is reasonable to regard speech recognition as a form of automated translation.
1.8EN16
As Hannu Toivonen writes, computational creativity is the twin of artificial intelligence: “Where artificial intelligence studies how to perform tasks which would be deemed intelligent if performed by a human, computational creativity studies performances which would be deemed creative if performed by a human” (Toivonen & Gross 2015, 265).
1.8EN17
To mention just one example, the Brains on Art group has created a “poem generator” that “produces poetry from the user’s brain waves.” See brainsonart.wordpress.com/2013/10/18/brain-poetry-2013