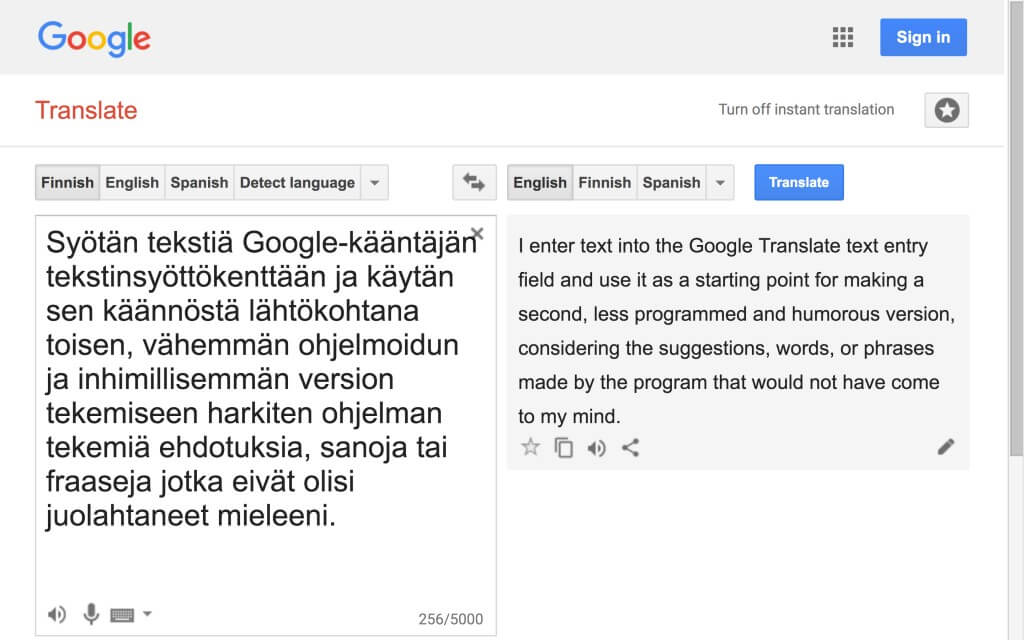
Tässä vastineessani fragmentti 25:een käsittelen teknogeneesia esittämällä sitä koskevan sovitusvideon ja sarjan kysymyksiä. Kysymykset koskevat sitä, mitä teknogeneesi (eli hypoteesi ihmisten ja teknologioiden yhteisevoluutiosta) voisi tarkoittaa tämän tutkimuksen yhteydessä. Käsitteenä teknogeneesi viittaa erittäin laajaan ja monitahoiseen ilmiöön, minkä takia sitä on lähestyttävä maltillisesti. How We Think on myös kokonaisvaltainen ja haastava teos, jonka tulkitseminen vaatii kärsivällistä ja huolellista lukemista. Näistä syistä olen tässä yhteydessä päättänyt matkia DAR:ia ja luoda oman Hayles-sovitukseni, olkoonkin että videotekstin muodossa.
{kind=link}
Video 3.5.1:een olen koonnut, kääntänyt ja sovittanut lähes kaikki katkelmat, joissa Hayles eksplisiittisesti käsittelee teknogeneesia. Kimmokkeen tähän on antanut fragmentti 25:n ja koko tämän tutkimuksen kuvastama inhimillisen kirjoittajan ja digitaalisen teknologian syvenevä suhde. Käännyn Haylesin puoleen saadakseni tarkempia käsitteellisiä välineitä tämän kehityskulun kuvaamiseen oman tutkimukseni puitteissa. Tätä tarkoitusta varten käytän tehokkaimpia tuntemiani keinoja, kääntämistä ja sovittamista. Tässä yhteydessä tämä strategia näyttäytyykin metodologisena välineenä, keinona omaksua, muokata ja uudelleen tulkita tietoa – sanalla sanoen ajatella.
Video 3.5.1 on kirjaimellisesti parafraasi, sillä siinä esitetyt ajatukset eivät ole omiani. Sen sijaan, että yksinkertaisesti viittaisin Haylesiin olen kuitenkin katsonut tarpeelliseksi esittää joitakin osia hänen tekstistään omin sanoin (monin paikoin parafraasi ei yllä alkuperäistekstin tyylikkyyteen). Tämän arveluttavan tekstuaalisen harjoituksen syy on se, että voidakseni toden teolla toimia Haylesin esiin tuomien monimutkaisten käsitteiden kanssa, saadakseni kiinni esitetyistä ajatusketjuista, on minun kajottava itse tekstiin materiaalina eikä pelkästään käsitteisiin. Viime kädessä tekstin pinnan myllääminen pyrkii luomaan etäisyyttä kirjoittajan esittämiin ajatuksiin ja tekemään tilaa omakohtaiselle reflektiolle. Tämän vastineen jälkimmäisessä osassa luettelenkin video 3.5.1:n valossa sarjan kysymyksiä, joilla pyrin kattavasti esittämään teknogeneesin relevanssin tälle tutkimukselle.
Hayles kirjoittaa teknogeneesista
19 kysymystä teknogeneesista
- Miten me tämän tutkimuksen kirjoittajat olemme kehittyneet konekääntämisen ja puheentunnistuksen kanssa?
- Miten olemme mukautuneet näihin teknologioihin? Voiko sanoa, että teknologiat ovat adaptoituneet meihin? Jos niin miten?
- Onko meistä tullut kirjoittajina mukautuvampia, joustavampia, digitaaliseen teknologiaan kytkeytymisemme seurauksena?
- Onko suhteemme tietokonekoodiin tai ymmärryksemme siitä muuttunut tutkimusprosessin myötä?
- Olemmeko omaksuneet teknologiasta malleja ja käyttäneet niitä muissa yhteyksissä?
- Olemmeko muuttuneet neurologisesti/fyysisesti/kognitiivisesti digitaalisen median laajamittaisen tutkimuskäytön myötä?
- Onko ymmärryksemme käyttämistämme koneista esineinä muuttunut?
- Miten reaktiomme yhdistyvät koneellisiin prosesseihin itse kirjoitusmenetelmissä?
- Voidaanko kirjoitusmenetelmät ymmärtää rakentaviksi teknogeneettisiksi väliintuloiksi? Mihin ne viime kädessä puuttuvat?
- Mitä keinoja meillä on arvioida tämän tutkimuksen puitteissa tapahtuvia teknogeneettisiä muutoksia?
- Olemmeko muodostaneet käsityksen siitä, mitä osaa koneellinen kognitio esittää kirjoitusprosesseissa?
- Olemmeko viime kädessä muuttuneet kirjoittajina? Jos niin miten?
- Voidaanko kirjoitusmenetelmiämme tai niitä mahdollistavia teknisiä järjestelmiä luonnehtia kompleksisiksi adaptiivisiksi järjestelmiksi?
- Mikä on suhteemme Googlen kaltaisiin monikansallisiin yrityksiin?
- Mihin niin kielellinen kuin biologinenkin mukautumisemme viime kädessä johtaa?
- Onko lähestymistapamme riittävän laaja, joustava ja hienovarainen kuvaamaan tutkimuksessa mahdollisesti tapahtuvia teknogeneettisiä muutoksia?
- Millaista ymmärrystä kirjoittamisesta ja lukemisesta tutkimus ehdottaa yleisemmällä tasolla?
- Mitä väliintulon muotoja käytössämme on tulevaisuudessa?
- Kehittävätkö kirjoitusmenetelmämme pikemminkin inhimillistä joustavuuttamme ja plastisuuttamme kuin kykyämme vastustaa digitaalisten medioiden ja niiden valmistajien vaikutusta?
Miten konekäännös on muuttunut
Aloittaakseni yllä lueteltujen kysymysten purkamisen viittaan tämän jakson päätteeksi muutamiin tämän tutkimuksen tekno-lingvistisiin näkökohtiin, jotka ovat merkityksellisiä teknogeneesin tarkastelulle. Tutkimuksen keskeinen digitaalinen media, algoritminen käännös, on jatkuvan muutoksen tilassa. Koneellinen kääntäminen ei ehkä ole vastannut Warren Weaverin ”Anti-Baabelin tornin” odotuksiin (3.5FI1), mutta se kehittyy edelleen sitä mukaan kun uudet, tehokkaammat ja tarkemmat lähestymistavat korvaavat aiempia.
Itse asiassa juuri tällä hetkellä, vuonna 2017, ”olemme keskellä vallankumousta koneellisessa kääntämisessä, ja maa liikkuu nopeasti jalkojemme alla”, kuten Rita Raley kuvaa (Raley 2018FI). Koneellisessa kääntämisessä siirrytään yleisesti vielä hiljattain tehokkaimpina pidetyistä tilastollisista menetelmistä neuraaliseen konekääntämiseen (termi vakiintumaton suomen kielessä), jossa hyödynnetään koneoppimisen uusia muotoja, erityisesti biologisten hermoverkkojen mallien pohjalta luotuja keinotekoisia hermoverkkoja (vrt. engl. neural networks) (3.5FI2). Matemaattisessa kielitieteessä käydään keskustelua siitä, kuinka merkittävä vallankumous neuraalinen konekääntäminen lopulta on, mutta kriittisiäkin kysymyksiä esittävät tahot ovat kuvanneet sitä ”konekääntämisen uudeksi paradigmaksi” tai ainakin ”askeleeksi eteenpäin” (Castilho et al. 2017, 109).
Algoritmisen käännöksen jatkuva muutos heijastuu esimerkiksi tapaan, jolla Rakkauden ABZ-näytelmäni konekäännökset ovat muuttuneet sinä aikana kun olen teetättänyt niitä Googlella. Vertaa esimerkiksi seuraavan monologikatkelman (näytelmäkäsikirjoituksen sivulta 69) Google-käännöksiä vuosilta 2010 ja 2017:
Rakkauden ABZ, 2008:
Kerro mulle, miks sun jutuissa on aina tällasia ylipitkiä monologeja? Häh?! Ne istuu vielä huonommin leffaan ku sun näytelmiis. Ja niissäkään ne ei toimi läheskään niin hyvin ku sä kuvittelet. Ja aina tää sama kaava: yksinäinen henkilö – useimmiten muuten mies – puhumassa jollekulle poissaolevalle tai vaan osittain läsnä olevalle toiselle. Tilittämässä. Mikä juttu tää oikein on? Onks sulla joku Hamlet-fiksaatio vai mitä?
Google-kääntäjä, 2010:
Tell me, why Sun is always desperate for Tallassee lengthy monologues? Huh?! They sit still worse movie ku Sun näytelmiis. And these statements are not working nearly as well-ku sä imagine. Tää and always the same formula: a lonely person – usually the other man – talking to somebody, but absent or in part to the presence of the other. Remitted. What is the correct thing Tää? Do you have a Hamlet-fixation or what?
Google-kääntäjä, 2017:
Tell me why the stuff is always overwhelming monologues? Huh?! They are sitting even worse in the movie theater. And even then, they do not work as well where you imagine. And always have the same formula: a lonely person – mostly a man – talking to someone who is absent or partially present to someone else. Being made available. What’s the deal right? Does anyone have any Hamlet fixation or what?
Nykyisen järjestelmän tuottama käännös ei ole kaikissa suhteissa parempi kuten viimeinen virke osoittaa. Uusi käännös on kuitenkin merkittävä siinä suhteessa, ettei se sisällä lainkaan kääntämättömiä, puhekielisiä ilmauksia. Juuri nämä kun rasittavat merkittävästi vuoden 2010 käännöstä. Yleisvaikutelmaksi jää, että nykyinen järjestelmä on tehokkaampi tuottamaan tekstiä, joka on kohdekielen mukaista – vaikkakin käännöstarkkuuden kustannuksella (3.5FI3).
Miten me olemme muuttuneet
Vaikeampaa on sen sijaan definitiivisesti sanoa, miten me, tämän tutkimuksen kirjoittajat – love.abz/(love.abz)3:n esiintyjät, DAR ja minä – olemme muuttuneet algoritmisten teknologioiden kanssa syntyneen teknogeneettisen kierteen myötä. Olen päättänyt olla haastattelematta love.abz/(love.abz)3:n esiintyjiä heidän kokemuksistaan live-kirjoittamisen psykofyysisistä vaikutuksista. Tästä syystä voin puhua vain omasta puolestani muutoksista, joita olen havainnut sisällytettyäni konekääntämisen ja sen läheisen kumppanin, puheentunnistuksen, kirjoitusprosesseihini.
Mitä tulee omaan kirjoittajuuteeni, pohdin olenko kirjoittajana muuttunut algoritmiseksi – tai ainakin algoritmisemmaksi. Toisin sanoen olenko ohjelmoinut itseni kirjoittamaan aikaisempaa automaattisemmin. Tuotanko tekstiä nopeammin? Onko teksti laadullisesti parempaa kuin ennen uusien teknologioiden (tai tekniikoiden) käyttöönottoa? Ennen kaikkea onko ajattelussani tapahtunut laadullisia muutoksia? Ja jos on, mikä on digitaalisen median rooli muutoksessa?
Nämä ovat tietysti kysymyksiä, joita esitän itselleni jatkuvasti kirjoittaessani tätä opinnäytettä. Ilmeinen vastaus on, että olen yhä inhimillinen kirjoittaja. Riippumatta siitä, miten paljon olen vuorovaikutuksessa kirjoittavien koneiden kanssa (3.5FI4.5), en tule omaksuneeksi niiltä kapasiteettia kirjoittaa jonkin algoritmin mukaan, en vaikka miten yrittäisin (3.5FI5). Kokonaan toinen kysymys on, miten algoritmisesti tuotetut tekstit ja digitaalisten laitteiden algoritmiset ominaisuudet – kuten automaattinen tekstintäydennys – muokkaavat käyttämiäni luonnollisia kieliä. Kuten Frederik Kaplan on huomauttanut, Googlen kaltaisten yritysten tarjoamat ohjelmat eivät ole pelkkiä palveluja, vaan viime kädessä ne pyrkivät tekemään kielistä taloudellisesti käyttökelpoisempia, algoritmisesti ”salonkikelpoisempia” (Kaplan 2014, 59–60).
Valitsemieni digitaalisten mediumien ”läpi, kanssa ja rinnalla” kirjoittaminen – palatakseni Haylesin muotoiluun (Hayles 2012, 1) – on johtanut ennen kaikkea, ja ehkä paradoksaalisesti, sekä tietoisuuden että epävarmuuden lisääntymiseen. Tarkoitan tällä lisääntynyttä tietoisuutta kielen muuttuvuudesta, labiiliudesta ja kontekstuaalisesta epävakaudesta, jonka jatkuva kääntäminen – ja varsinkin itsekääntäminen – tuo mukanaan. Tämä tietoisuus liittyy aivan tämän tutkimushankkeen alussa ilmenneisiin pohdintoihin tekstuaalisuuden luonteesta (3.5FI6).
Notes
3.5FI1
Kuten Rita Raley kirjoittaa, Weaverin vuonna 1955 ilmaisema toive on, että koneellinen käännös mahdollistaisi monikielisten tekstien perusmerkityksen välittämisen automatisoidusti. Siten se edistäisi tekstien saatavuutta, kansainvälistä kulttuurinvaihtoa ja yhteisymmärrystä – viime kädessä ihmisten vapaata kommunikaatiota. (Raley 2003, 291.)
3.5FI2
Christopher Manning on kuvannut neuraalista konekääntämistä (engl. lyh. NMT) ”lähestymistavaksi, jossa [koneellisen kääntämisen] koko prosessi mallinnetaan yhden suuren keinotekoisen neuroverkon kautta” (Neural Machine Translation and Models with Attention 3.4.2017, painotus alkutekstissä). Google on korvannut aiemmat tilastolliset menetelmänsä omalla NMT-järjestelmällä, ei tosin kaikissa kielipareissaan (Lewis-Kraus 2016). Microsoft-kääntäjä on sekin siirtynyt NMT-järjestelmään. Verkkosivuillaan yhtiö lupaa ”merkittävää edistystä käännösten laadussa” tilastollisiin menetelmiin verrattuna: ”Neuroverkot ottavat paremmin haltuun koko lauseen kontekstin [-] ja tarjoavat inhimillisemmiltä kuulostavia tuloksia” (Microsoft Translator launching Neural Network based translations for all its speech languages 15.11.2016).
3.5FI3
Tällä hetkellä Google käyttää edelleen suomen ja englannin välisissä käännöksissään tilastollista menetelmää neuraalisen menetelmän sijaan (Google 1.7.2017).
3.5FI4.5
Kirjoittavalla koneella tarkoitan tässä yhteydessä konetta, jolla on kapasiteetti myötävaikuttaa kirjoitusprosessiin tuomalla siihen aineksia – yksittäisiä sanoja, fraaseja, kokonaisia lauseitakin – joita inhimillinen kirjoittaja ei olisi ilman sitä tullut sisällyttäneeksi tekstiinsä (ks. 2.7).
3.5FI5
Ajatus inhimillisestä algoritmisesta kirjoittamisesta on kutkuttava, samoin kuin on ajatus algoritmista dramaturgisena työkaluna, eräänlaisena esityskäsikirjoituksena tai scorena. Ks. 2.6.
3.5FI6
Viittaan erityisesti Joseph Grigelyn kirjan Textualterity – Art, Theory, and Textual Criticism lukuun ”The Textual Event” (”Tekstuaalinen tapahtuma”), jossa Grigely kirjoittaa tekstin rajoista, tekstuaalisesta epävakaudesta ja tekstistä epävakauden tapahtumapaikkana: ”Ei ole oikeaa tekstiä, ei lopullista tekstiä, ei alkuperäistä tekstiä vaan ainoastaan erilaisia tekstejä, jotka ajelehtivat niiden samankaltaisissa eroissa” (Grigely 1995, 119).